Apache PDFBox extract text from PDF Document
This tutorial demonstrates how to use Apache PDFBox to extract text from a PDF document. The first example extracts all text from a PDF document. The second example extracts text from a specific area.
Maven Dependencies
We use Apache Maven to manage our project dependencies. Make sure the following dependencies reside on the class-path.
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox</artifactId>
<version>2.0.8</version>
</dependency>Extract Text from PDF document
In the following examples we’ll be using the following PDF document to extract the text from.
Apache PDFBox Extract all text from PDF
We can use the PDFTextStripper to filter out all the text from the PDF document.
package com.memorynotfound.pdf.pdfbox;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.text.PDFTextStripper;
import java.io.File;
import java.io.IOException;
public class ExtractText {
public static void main(String[] args) throws Exception{
try (PDDocument document = PDDocument.load(new File("/tmp/example.pdf"))) {
if (!document.isEncrypted()) {
PDFTextStripper tStripper = new PDFTextStripper();
String pdfFileInText = tStripper.getText(document);
String lines[] = pdfFileInText.split("\\r?\\n");
for (String line : lines) {
System.out.println(line);
}
}
} catch (IOException e){
System.err.println("Exception while trying to read pdf document - " + e);
}
}
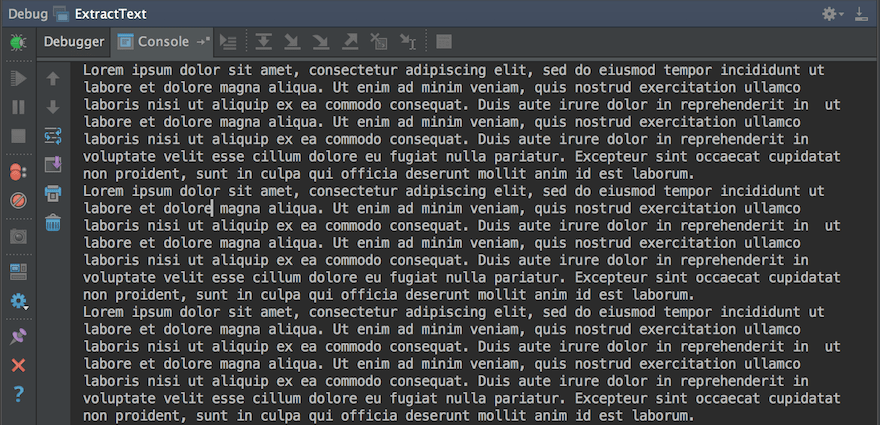
}Output
You can see that the entire content of the PDF document is extracted.
Apache PDFBox Extract text from PDF by area
We can use the PDFTextStripperByArea to extract text from a specific area.
package com.memorynotfound.pdf.pdfbox;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.pdmodel.PDPage;
import org.apache.pdfbox.text.PDFTextStripperByArea;
import java.awt.*;
import java.io.File;
import java.io.IOException;
public class ExtractTextByArea {
public static void main(String[] args) throws Exception{
try (PDDocument document = PDDocument.load(new File("/tmp/example.pdf"))) {
if (!document.isEncrypted()) {
PDFTextStripperByArea stripper = new PDFTextStripperByArea();
stripper.setSortByPosition(true);
Rectangle rect = new Rectangle(10, 60, 600, 140);
stripper.addRegion("class1", rect);
PDPage firstPage = document.getPage(0);
stripper.extractRegions( firstPage );
System.out.println("Text in the area:" + rect);
System.out.println(stripper.getTextForRegion( "class1"));
}
} catch (IOException e){
System.err.println("Exception while trying to read pdf document - " + e);
}
}
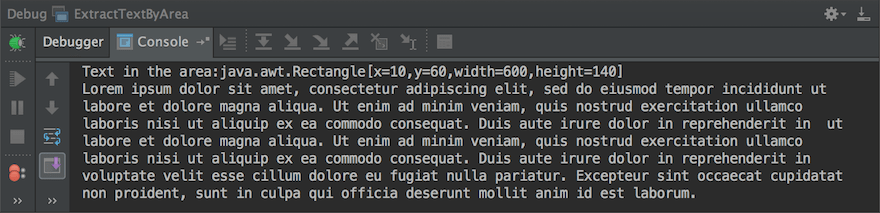
}Output
You can see that only the first paragraph of the PDF document is extracted.
References
- Apache PdfBox Official Website
- Apache PdfBox API Javadoc
- Apache PdfBox read PDF document
- Apache PdfBox create PDF document
- PDFTextStripper JavaDoc
- PDFTextStripperByArea JavaDoc
Download
Download it – apache pdfbox extract text pdf document