Apache PDFBox Split PDF Document in Java
The following example demonstrates how to use Apache PdfBox to split a PDF Document.
Maven Dependencies
We use Apache Maven to manage our project dependencies. Make sure the following dependencies reside on the class-path.
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox</artifactId>
<version>2.0.8</version>
</dependency>Apache PDFBox Split All Pages of PDF Document
We can split all pages of the PDF document using the Splitter class.
package com.memorynotfound.pdf.pdfbox;
import org.apache.pdfbox.multipdf.Splitter;
import org.apache.pdfbox.pdmodel.PDDocument;
import java.io.File;
import java.io.IOException;
import java.util.Iterator;
import java.util.List;
public class SplitPdf {
public static void main(String[] args) throws Exception{
try (PDDocument document = PDDocument.load(new File("/tmp/example.pdf"))) {
// Instantiating Splitter class
Splitter splitter = new Splitter();
// splitting the pages of a PDF document
List<PDDocument> Pages = splitter.split(document);
// Creating an iterator
Iterator<PDDocument> iterator = Pages.listIterator();
// Saving each page as an individual document
int i = 1;
while (iterator.hasNext()) {
PDDocument pd = iterator.next();
pd.save("/tmp/split_" + i + ".pdf");
i++;
}
} catch (IOException e){
System.err.println("Exception while trying to read pdf document - " + e);
}
}
}Output
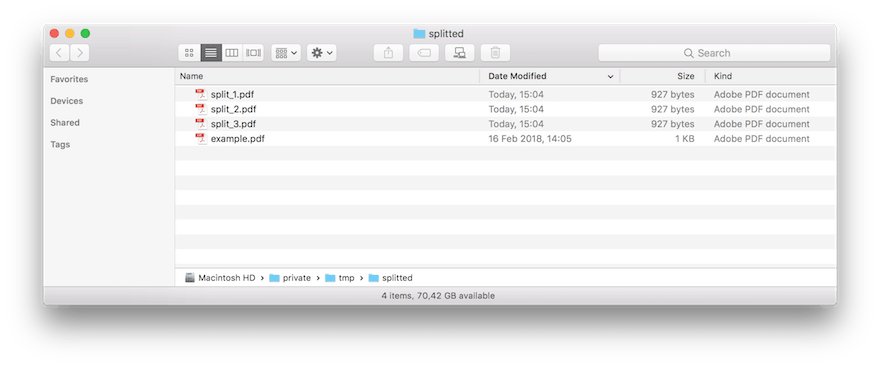
When we run the previous application all pages of the PDF document are splitted in their own PDF document. You can see the result in the following image.
Apache PDFBox Split Specific Page of PDF Document
We can split only specific pages of the PDF document using the Splitter class by setting the setStartPage(); and setEndPage(); methods.
package com.memorynotfound.pdf.pdfbox;
import org.apache.pdfbox.multipdf.Splitter;
import org.apache.pdfbox.pdmodel.PDDocument;
import java.io.File;
import java.io.IOException;
import java.util.Iterator;
import java.util.List;
public class SplitPdf {
public static void main(String[] args) throws Exception{
try (PDDocument document = PDDocument.load(new File("/tmp/example.pdf"))) {
// Instantiating Splitter class
Splitter splitter = new Splitter();
splitter.setStartPage(2);
splitter.setEndPage(2);
// splitting the pages of a PDF document
List<PDDocument> Pages = splitter.split(document);
// Creating an iterator
Iterator<PDDocument> iterator = Pages.listIterator();
// Saving each page as an individual document
int i = 1;
while (iterator.hasNext()) {
PDDocument pd = iterator.next();
pd.save("/tmp/split_" + i + ".pdf");
i++;
}
} catch (IOException e){
System.err.println("Exception while trying to read pdf document - " + e);
}
}
}Output
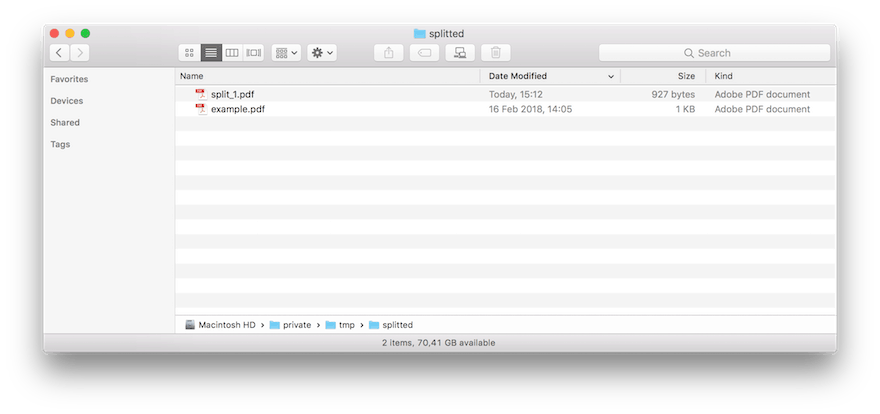
When we run the previous application only a specific page of the PDF document is splitted in his own PDF document. You can see the result in the following image.
References
- Apache PdfBox Official Website
- Apache PdfBox API Javadoc
- Apache PdfBox read PDF document
- Apache PdfBox create PDF document
- Splitter JavaDoc
Download
Download it – apache pdfbox split pdf document java